Useful Functions in R for Manipulating Text Data
February 27, 2014 12 Comments
Introduction
In my current job, I study HIV at the genetic and biochemical levels. Thus, I often work with data involving the sequences of nucleotides or amino acids of various patient samples of HIV, and this type of work involves a lot of manipulating text. (Strictly speaking, I analyze sequences of nucleotides from DNA that are reverse-transcribed from the HIV’s RNA.) In this post, I describe some common functions in R that I often use for text processing.
Obtaining Basic Information about Character Variables
In R, I often work with text data in the form of character variables. To check if a variable is a character variable, use the is.character() function.
> year = 2014 > is.character(year) [1] FALSE
If a variable is not a character variable, you can convert it to a character variable using the as.character() function.
> year.char = as.character(year) > is.character(year.char) [1] TRUE
A basic piece of information about a character variable is the number of characters that exist in this string. Use the nchar() function to obtain this information.
> nchar(year.char) [1] 4
Combining and Splitting Text
I often need to combine several character variables into one string, and the paste() function is useful for that. Notice my use of the “sep =” option to specify that I want to separate the variables with 1 space.
> first = 'The' > second = 'Chemical' > third = 'Statistician' > my.name = paste(first, second, third, sep = ' ') > my.name [1] "The Chemical Statistician"
The opposite task is to split 1 string into many shorter strings. The strsplit() function is useful for that. Notice my use of the “split = ” option to specify that a single space is the delimiter. You can split multiple variables simultaneously by combining them with the c() function. Allow me to first create a new variable called real.name to illustrate this capability.
> real.name = paste('Eric', 'Cai', sep = ' ')
> parts = strsplit(c(my.name, real.name), split = ' ')
> parts
[[1]]
[1] "The" "Chemical" "Statistician"
[[2]]
[1] "Eric" "Cai"
The output is a list of objects. To obtain the individual strings, simply slice each object out of the list with double square brackets, then extract each string from each list with single square brackets. For example, to obtain the 2nd string from the decomposition of my.name,
> parts[[1]][2] [1] "Chemical"
Another way to split a string is to use the scan() function. Note, however, that this option is much slower, and I discourage using it with apply() to split 
> my.name.parts = scan(text = my.name, what = 'character', sep = ' ') Read 3 items > my.name.parts [1] "The" "Chemical" "Statistician" > my.name.parts[2] [1] "Chemical"
Pattern Matching and Manipulation
A common task in my job is determining whether or not a sequence of 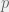

> x = 'ATCG' > y = 'GGACTCTAAATCCGTACTATCGTCATCGTTTTTCCT' > z = 'CTATCGGGTAGCT' > grepl(x, c(y, z)) [1] TRUE TRUE
If you want to determine precisely where “x” is located along “y” and along “z”, use the gregexpr() function.
> gregexpr(x, c(y, z)) [[1]] [1] 19 25 attr(,"match.length") [1] 4 4 attr(,"useBytes") [1] TRUE [[2]] [1] 3 attr(,"match.length") [1] 4 attr(,"useBytes") [1] TRUE
The output of gregexpr(x, c(y, z)) is a list of 2 objects.
- The first object contains the positional information about the pattern “x” in the variable “y”.
- “x” appears twice in the variable “y” – at positions 19 and 25. (Specifically, the “A” in x = ‘ATCG’ appears at positions 19 and 25.)
- The second object contains the positional information about the pattern “x” in the variable “z”.
To extract these positions, you must first slice the list into its 2 objects – use double square brackets to do this. Then, you can extract the positions from each object – use single square brackets to do this. For simplicity, let’s assign the output of gregexpr(x, c(y, z)) to a variable named “pos”.
> pos = gregexpr(x, c(y, z)) > pos[[1]] [1] 19 25 attr(,"match.length") [1] 4 4 attr(,"useBytes") [1] TRUE > pos[[1]][1] [1] 19 > pos[[1]][2] [1] 25
If you want to extract a portion of a string, use the substr() function. For example, if I know that the first 3 nucleotides of a particular DNA sequence are junk, I would want to discard them and extract the rest of that sequence only. Let’s use the variable “y” to illustrate this.
> y [1] "GGACTCTAAATCCGTACTATCGTCATCGTTTTTCCT" > substr(y, 4, nchar(y)) [1] "CTCTAAATCCGTACTATCGTCATCGTTTTTCCT"
Further Information
John Myles White, who co-wrote the excellent “Machine Learning for Hackers” with Drew Conway, has a nice blog entry on some other useful functions for text processing in R. If you have any more suggestions, please share them in the comments!

a simple function regmatches() can use the return value from gregexpr() to extract text. Basically it’s the same as the substr() + gregexpr().
Thanks for sharing, Xianbin! That’s good to know!
Not sure if these examples were picked just for sake of example, but if you’re finding yourself working with R and doing all sorts of things over biological sequences (nucleotides, amino acids), it’d be worth your while to check out the infrastructure provided in Bioconductor for these purposes: namely the Biostrings package. It plays well with the IRanges and BSgenome stuff to do all sorts of things you probably would end up having to right custom functions for:
http://bioconductor.org/packages/release/bioc/html/Biostrings.html
Thanks for sharing this, Steve!
Yes, the functions that I demonstrated in this post are actual functions that I regularly use in my job to process text data from nucleotide and amino acid sequences. I will check out the Biostrings package and see how it can help in my lab’s work!
Hi Eric,
Are you familiar with regular expressions? They are extremely helpful in manipulating text data as well.
For example, where you declared y variable as GGACTCTAAATCCGTACTATCGTCATCGTTTTTCCT
TA TA
Suppose I want to look for the pattern TA_TA but where _ is any letter and I don’t really care what letter it is. I just want to know how if the pattern TA any letter TA occurs.
test<-grepl('TA\\wTA',y)
It will say true in R.
I forgot to post this in the previous post but the following is a good website about regular expressions:
http://www.rexegg.com/regex-quickstart.html
Thanks for sharing these resources, Vi! No, I am not familiar with regular expressions, so thanks for telling me about this nice web page!
As always, I enjoy learning from you. Thanks for being a helpful reader!
shameless self-advertising: this whole book is on text processing with R:
Gries, Stefan Th. 2009. _Quantitative corpus linguistics with R: a practical introduction_. London & New York: Routledge, Taylor & Francis Group, pp. 256. This book is now listed on the CRAN Task View on Natural Language Processing; its companion website is at http://www.linguistics.ucsb.edu/faculty/stgries/research/qclwr/qclwr.html.
The most important thing to us is sharing knowledge, so you’re welcomed to tell us about your book, Stefan! It’s wonderful to hear that R is helpful for linguistics!
You should also check out the package seqinr. It has a higher mempry profile for sequences than Biostrings, but has the benefit or allowing any character you want, whereas Biostrings limits a DNAstring to ACTG. GenomicRanges is also a package you really can’t go past. One of my favourite graphing packes is ggbio (basically a wrapper for ggplots to allow bioconductor data types), it has awesome plotting capabilities like manhattan plots and kayrograms.
Wow! Other than ggplots, I have not heard of any of the other things that you mentioned, Jeremy! Much more for me to learn, and thanks to you for telling us about all of these things!
Reblogged this on nishant@analyst.