Statistics Lesson and Warning of the Day – Confusion Between the Median and the Average
April 25, 2014 4 Comments
Yesterday, I attended an interesting seminar called “Transforming Healthcare through Big Data” at the Providence Health Care Research Institute‘s 2014 Research Day. The seminar was delivered by Martin Kohn from Jointly Health, and I enjoyed it overall. However, I noticed a glaring error about basic statistics that needs correction.
Martin wanted to highlight the overconfidence that many doctors have about their abilities, and he quoted Vinod Kohsla, the co-founder of Sun Microsystems, who said, “50% of doctors are below average.” Martin then presented a study showing an absurdly high percentage of doctors who think that they are “above average”. A Twitter conversation between attendees of a TED conference in San Francisco and Vinod himself confirms this quotation.
The statement “50% of doctors are below average” is wrong in general. By definition, 50% of any population is below the median, and the median is only equal to the average if the population is symmetric. (Examples of symmetric probability distributions are the normal distribution and the Student’s t-distribution.) Vinod meant to say that “50% of doctors are below the median”, and he confirmed this in the aforementioned Twitter conversation; I am disappointed that he justified this mistake by claiming that it would be less understood. I think that a TED audience would know what “median” means, and those who don’t can easily search for its meaning online or in books on their own.
In communicating truth, let’s use the correct vocabulary.
 ,
, . In other words,
. In other words,  is the design matrix, and the element in row
is the design matrix, and the element in row  and column
and column  of this design matrix is the
of this design matrix is the  predictor being evaluated in the
predictor being evaluated in the  basis function. (In this case, there is 1 predictor per datum.)
basis function. (In this case, there is 1 predictor per datum.)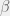 , can be estimated by
, can be estimated by .
. , but
, but  was obtained, I encourage you to review least-squares estimation and the derivation of the estimator of the coefficient vector in linear regression.
was obtained, I encourage you to review least-squares estimation and the derivation of the estimator of the coefficient vector in linear regression. notation; unfortunately, this notation is not clearly explained in most textbooks or web sites about
notation; unfortunately, this notation is not clearly explained in most textbooks or web sites about  is the number of levels in each factor; note that the
is the number of levels in each factor; note that the  and
and 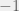 .
.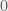 , and
, and  is the number of factors in the experiment
is the number of factors in the experiment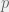 is the number of times that the full factorial design is fractionated by
is the number of times that the full factorial design is fractionated by 
 .
. ). Thus,
). Thus, , then the fraction of treatments that is used is
, then the fraction of treatments that is used is  .
. , then the fraction of treatments that is used is
, then the fraction of treatments that is used is  .
. design is often called a half-fraction design.
design is often called a half-fraction design. design is often called a quarter-fraction design.
design is often called a quarter-fraction design. , then
, then design uses one-third of all possible treatments.
design uses one-third of all possible treatments. design uses one-ninth of all possible treatments.
design uses one-ninth of all possible treatments. random variables,
random variables,  , are independent and identically distributed,
, are independent and identically distributed, , is approximately normal, and this approximation is better as
, is approximately normal, and this approximation is better as 
![\phi_j(x) = exp[-(x - \mu_j)^2 \div 2\sigma^2]](https://s0.wp.com/latex.php?latex=%5Cphi_j%28x%29+%3D+exp%5B-%28x+-+%5Cmu_j%29%5E2+%5Cdiv+2%5Csigma%5E2%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)
 in this basis function determines the spacing between the different basis functions that combine to form the model.
in this basis function determines the spacing between the different basis functions that combine to form the model. ; the scaling factor ensures that the normal PDF integrates to 1 over its support set. In a linear basis function model, the regression coefficients are the weights for the basis functions, and these weights will scale Gaussian basis functions to fit the data that are local to
; the scaling factor ensures that the normal PDF integrates to 1 over its support set. In a linear basis function model, the regression coefficients are the weights for the basis functions, and these weights will scale Gaussian basis functions to fit the data that are local to 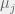 . Thus, there is no need to include that scaling factor of
. Thus, there is no need to include that scaling factor of 


Recent Comments