Mathematical Statistics Lesson of the Day – Sufficient Statistics
November 5, 2014 4 Comments
*Update on 2014-11-06: Thanks to Christian Robert’s comment, I have removed the sample median as an example of a sufficient statistic.
Suppose that you collected data
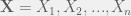
in order to estimate a parameter 
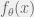

Let

be a statistic based on 


If the conditional PDF
![h_\theta(\mathbf{X}) = f_\theta(x) \div g_\theta[T(\mathbf{X})]](https://s0.wp.com/latex.php?latex=h_%5Ctheta%28%5Cmathbf%7BX%7D%29+%3D+f_%5Ctheta%28x%29+%5Cdiv+g_%5Ctheta%5BT%28%5Cmathbf%7BX%7D%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)
is independent of 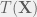

and 
Intuitively, this means that
Often, the sufficient statistic for
- sample mean
sample median– removed thanks to comment by Christian Robert (Xi’an)- sample minimum
- sample maximum
If such a summary statistic is sufficient for 
*This above definition holds for discrete and continuous random variables.

 is the sample standard deviation and
is the sample standard deviation and  is the sample mean.
is the sample mean.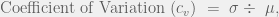
 is the random variable’s standard deviation and
is the random variable’s standard deviation and  is the random variable’s expected value.
is the random variable’s expected value. to obtain
to obtain  . For a sufficiently large
. For a sufficiently large 
 , are independent and identically distributed,
, are independent and identically distributed, , is approximately normal, and this approximation is better as
, is approximately normal, and this approximation is better as 

Recent Comments