How to Get the Frequency Table of a Categorical Variable as a Data Frame in R
February 3, 2015 32 Comments
Introduction
One feature that I like about R is the ability to access and manipulate the outputs of many functions. For example, you can extract the kernel density estimates from density() and scale them to ensure that the resulting density integrates to 1 over its support set.
I recently needed to get a frequency table of a categorical variable in R, and I wanted the output as a data table that I can access and manipulate. This is a fairly simple and common task in statistics and data analysis, so I thought that there must be a function in Base R that can easily generate this. Sadly, I could not find such a function. In this post, I will explain why the seemingly obvious table() function does not work, and I will demonstrate how the count() function in the ‘plyr’ package can achieve this goal.
The Example Data Set – mtcars
Let’s use the mtcars data set that is built into R as an example. The categorical variable that I want to explore is “gear” – this denotes the number of forward gears in the car – so let’s view the first 6 observations of just the car model and the gear. We can use the subset() function to restrict the data set to show just the row names and “gear”.
> head(subset(mtcars, select = 'gear'))
gear
Mazda RX4 4
Mazda RX4 Wag 4
Datsun 710 4
Hornet 4 Drive 3
Hornet Sportabout 3
Valiant 3
 ,
, being called the dependent variable and
being called the dependent variable and  being called the independent variable. This terminology holds true for more complicated functions with multiple variables, such as in
being called the independent variable. This terminology holds true for more complicated functions with multiple variables, such as in 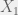 and
and  are independent if their joint distribution is simply a product of their marginal distributions, and they are dependent if otherwise. Thus, the usage of “independent variable” for a regression model with 2 predictors becomes problematic if the model assumes that the predictors are random variables; a random effects model is an example with such an assumption. An obvious question for such models is whether or not the independent variables are independent, which is a rather confusing question with 2 uses of the word “independent”. A better way to phrase that question is whether or not the predictors are independent.
are independent if their joint distribution is simply a product of their marginal distributions, and they are dependent if otherwise. Thus, the usage of “independent variable” for a regression model with 2 predictors becomes problematic if the model assumes that the predictors are random variables; a random effects model is an example with such an assumption. An obvious question for such models is whether or not the independent variables are independent, which is a rather confusing question with 2 uses of the word “independent”. A better way to phrase that question is whether or not the predictors are independent. and the terms “explanatory variables”, “predictor variables”, “predictors”, “covariates”, or “factors” for
and the terms “explanatory variables”, “predictor variables”, “predictors”, “covariates”, or “factors” for  .
. notation; unfortunately, this notation is not clearly explained in most textbooks or web sites about
notation; unfortunately, this notation is not clearly explained in most textbooks or web sites about  is the number of levels in each factor; note that the
is the number of levels in each factor; note that the  and
and 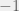 .
.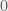 , and
, and  is the number of factors in the experiment
is the number of factors in the experiment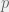 is the number of times that the full factorial design is fractionated by
is the number of times that the full factorial design is fractionated by 
 .
. ). Thus,
). Thus, , then the fraction of treatments that is used is
, then the fraction of treatments that is used is  .
. , then the fraction of treatments that is used is
, then the fraction of treatments that is used is  .
. design is often called a half-fraction design.
design is often called a half-fraction design. design is often called a quarter-fraction design.
design is often called a quarter-fraction design. , then
, then design uses one-third of all possible treatments.
design uses one-third of all possible treatments. design uses one-ninth of all possible treatments.
design uses one-ninth of all possible treatments.



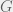 factors and the response, where
factors and the response, where 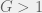 . On first instinct, you may be tempted to conduct
. On first instinct, you may be tempted to conduct 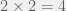 treatments, each being a combination of 1 level from the first factor and 1 level from the second factor. Since this is a full factorial design, experimental units are independently assigned to all treatments. The 2-factor ANOVA model is commonly used to analyze data from such designs.
treatments, each being a combination of 1 level from the first factor and 1 level from the second factor. Since this is a full factorial design, experimental units are independently assigned to all treatments. The 2-factor ANOVA model is commonly used to analyze data from such designs. experimental units into
experimental units into  pairs. Within each pair (i.e. each block), the
pairs. Within each pair (i.e. each block), the 

Recent Comments