Most SAS procedures require the
RUN;
statement to signal their termination. However, there are some notable exceptions to this.
I have written about PROC SQL many times on my blog, and this procedure requires the
QUIT;
statement instead.
It turns out that there is another set of statistical procedures that require the QUIT statement, and some of them are very common. They are called interactive procedures, and they include PROC REG, PROC GLM, and PROC ANOVA. If you end them with RUN rather than QUIT, then you will run into problems with displaying further output. For example, if you try to output a data set from one such PROC and end it with the RUN statement, then you will get this error message:
ERROR: You cannot open WORK.MYDATA.DATA for input access with record-level
control because WORK.MYDATA.DATA is in use by you in resource environment
REG.
WORK.MYDATA cannot be opened.
You will also notice that the Program Editor says “PROC … running” in its banner when you end such a PROC with RUN rather than QUIT.
I don’t like this exception, but, alas, it does exist. You can find out more about these interactive procedures in SAS Usage Note #37105. As this note says, the ANOVA, ARIMA, CATMOD, FACTEX, GLM, MODEL, OPTEX, PLAN, and REG procedures are interactive procedures, and they all require the QUIT statement for termination.
PROC IML is not mentioned in that usage note, but this procedure also requires the QUIT statement. Rick Wicklin has written an article about this on his blog, The DO Loop.
 and
and  , the correlation coefficient between them is defined as their covariance scaled by the product of their standard deviations. Algebraically, this can be expressed as
, the correlation coefficient between them is defined as their covariance scaled by the product of their standard deviations. Algebraically, this can be expressed as![\rho_{X, Y} = \frac{Cov(X, Y)}{\sigma_X \sigma_Y} = \frac{E[(X - \mu_X)(Y - \mu_Y)]}{\sigma_X \sigma_Y}](https://s0.wp.com/latex.php?latex=%5Crho_%7BX%2C+Y%7D+%3D+%5Cfrac%7BCov%28X%2C+Y%29%7D%7B%5Csigma_X+%5Csigma_Y%7D+%3D+%5Cfrac%7BE%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D%7D%7B%5Csigma_X+%5Csigma_Y%7D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.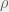 is the Pearson correlation coefficient, which is defined as the sample covariance between
is the Pearson correlation coefficient, which is defined as the sample covariance between 
 .
.
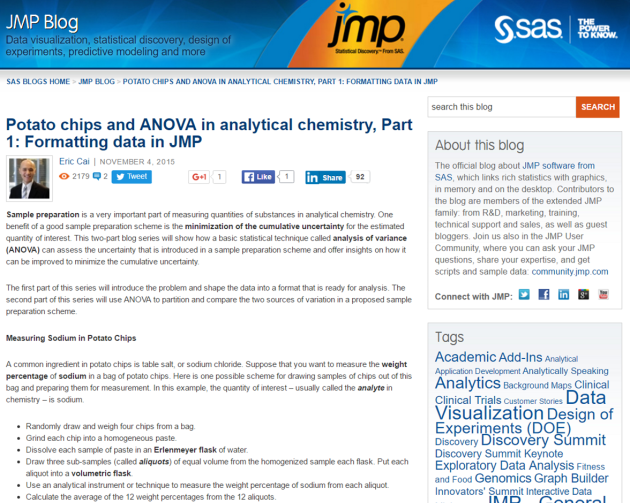

![P[(\text{Winner}_1 = \text{Home Team}_1) \cap (\text{Winner}_2 = \text{Home Team}_2) \cap \ldots \cap (\text{Winner}_{15}= \text{Home Team}_{15})]](https://s0.wp.com/latex.php?latex=P%5B%28%5Ctext%7BWinner%7D_1+%3D+%5Ctext%7BHome+Team%7D_1%29+%5Ccap+%28%5Ctext%7BWinner%7D_2+%3D+%5Ctext%7BHome+Team%7D_2%29+%5Ccap+%5Cldots+%5Ccap+%28%5Ctext%7BWinner%7D_%7B15%7D%3D+%5Ctext%7BHome+Team%7D_%7B15%7D%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)
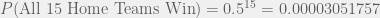
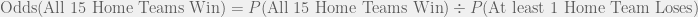

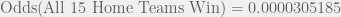
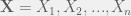
 . Let
. Let 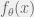 be the probability density function (PDF) or probability mass function (PMF) for
be the probability density function (PDF) or probability mass function (PMF) for  .
.
 .
. is a complete and minimal sufficient statistic, then
is a complete and minimal sufficient statistic, then 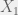 and
and  , from the normal distribution
, from the normal distribution  , where
, where  is unknown. Then the statistic
is unknown. Then the statistic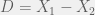
 .
. does not depend on
does not depend on 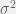 is unknown, then
is unknown, then 
Recent Comments