I previously introduced the concept of chirality and how it is a property of any molecule with only 1 stereogenic centre. (A molecule with  stereogenic centres may or may not be chiral, depending on its stereochemistry.) I also defined 2 stereoisomers as enantiomers if they are non-superimposable mirror images of each other. (Recall that chirality in inorganic chemistry can arise in 2 different ways.)
stereogenic centres may or may not be chiral, depending on its stereochemistry.) I also defined 2 stereoisomers as enantiomers if they are non-superimposable mirror images of each other. (Recall that chirality in inorganic chemistry can arise in 2 different ways.)
It is possible for 2 stereoisomers to NOT be enantiomers; in fact, such stereoisomers are called diastereomers. Yes, I recognize that defining something as the negation of something else is unusual. If you have learned set theory or probability (as I did in my mathematical statistics classes) then consider the set of all pairs of the stereoisomers of one compound – this is the sample space. The enantiomers form a set within this sample space, and the diastereomers are the complement of the enantiomers.
It is important to note that, while diastereomers are not mirror images of each other, they are still non-superimposable. Diastereomers often (but not always) arise from stereoisomers with 2 or more stereogenic centres; here is an example of how they can arise. (A pair of cis/trans-isomers are also diastereomers, despite not having any stereogenic centres.)
1) Consider a stereoisomer with 2 tetrahedral stereogenic centres and no meso isomers*. This isomer has  stereoisomers, where
stereoisomers, where  denotes the number of stereogenic centres.
denotes the number of stereogenic centres.
2) Find one pair of enantiomers based on one of the stereogenic centres.
3) Find the other pair enantiomers based on the other stereogenic centre.
4) Take any one molecule from Step #2 and any one molecule from Step #3. These cannot be mirror images of each other. (One molecule cannot have 2 different mirror images of itself.) These 2 molecules are diastereomers.
Think back to my above description of enantiomers as a proper subset within the sample space of the pairs of one set of stereoisomers. You can now see why I emphasized that the sample space consists of pairs, since multiple different pairs of stereoisomers can form enantiomers. In my example above, Steps #2 and #3 produced 2 subsets of enantiomers. It should be clear by now that enantiomers and diastereomers are defined as pairs. To further illustrate this point,
a) call the 2 molecules in Step#2 A and B.
b) call the 2 molecules in Step #3 C and D.
A and B are enantiomers. A and C are diastereomers. Thus, it is entirely possible for one molecule to be an enantiomer with a second molecule and a diastereomer with a third molecule.
Here is an example of 2 diastereomers. Notice that they have the same chemical formula but different 3-dimensional orientations – i.e. they are stereoisomers. These stereoisomers are not mirror images of each other, but they are non-superimposable – i.e. they are diastereomers.

(-)-Threose

(-)-Erythrose
Images courtesy of Popnose, DMacks and Edgar181 on Wikimedia. For brevity, I direct you to the Wikipedia entry for diastereomers showing these 4 images in one panel.
In a later Chemistry Lesson of the Day on optical rotation (a.k.a. optical activity), I will explain what the (-) symbol means in the names of those 2 diastereomers.
*I will discuss meso isomers in a separate lesson.

![P[(\text{Winner}_1 = \text{Home Team}_1) \cap (\text{Winner}_2 = \text{Home Team}_2) \cap \ldots \cap (\text{Winner}_{15}= \text{Home Team}_{15})]](https://s0.wp.com/latex.php?latex=P%5B%28%5Ctext%7BWinner%7D_1+%3D+%5Ctext%7BHome+Team%7D_1%29+%5Ccap+%28%5Ctext%7BWinner%7D_2+%3D+%5Ctext%7BHome+Team%7D_2%29+%5Ccap+%5Cldots+%5Ccap+%28%5Ctext%7BWinner%7D_%7B15%7D%3D+%5Ctext%7BHome+Team%7D_%7B15%7D%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)
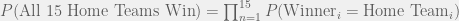
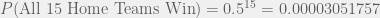
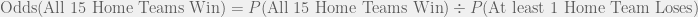

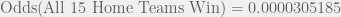
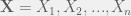
 . Let
. Let 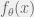 be the probability density function (PDF)* for
be the probability density function (PDF)* for  .
.
 .
.![E_\theta \{g[T(\mathbf{X})]\} = 0, \ \ \forall \ \theta,](https://s0.wp.com/latex.php?latex=E_%5Ctheta+%5C%7Bg%5BT%28%5Cmathbf%7BX%7D%29%5D%5C%7D+%3D+0%2C+%5C+%5C+%5Cforall+%5C+%5Ctheta%2C&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P \{g[T(\mathbf{X})]\} = 0] = 1,](https://s0.wp.com/latex.php?latex=P+%5C%7Bg%5BT%28%5Cmathbf%7BX%7D%29%5D%5C%7D+%3D+0%5D+%3D+1%2C&bg=f0f0f0&fg=555555&s=0&c=20201002)
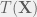 is said to be complete. To deconstruct this esoteric mathematical statement,
is said to be complete. To deconstruct this esoteric mathematical statement,  be a measurable function
be a measurable function![g[T(\mathbf{X})]](https://s0.wp.com/latex.php?latex=g%5BT%28%5Cmathbf%7BX%7D%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) to form an unbiased estimator of the zero function,
to form an unbiased estimator of the zero function,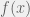 that is continuous on the interval
that is continuous on the interval ![[x_1, x_2]](https://s0.wp.com/latex.php?latex=%5Bx_1%2C+x_2%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) , where
, where 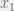 and
and 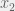 are any 2 points in the domain of
are any 2 points in the domain of 
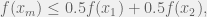
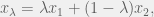 where
where 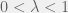 .
.

 with a finite expected value and for any convex function
with a finite expected value and for any convex function  ,
,![E[g(Y)] \geq g[E(Y)]](https://s0.wp.com/latex.php?latex=E%5Bg%28Y%29%5D+%5Cgeq+g%5BE%28Y%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.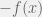 is convex. Thus, Jensen’s inequality can also be stated for concave functions. For any random variable
is convex. Thus, Jensen’s inequality can also be stated for concave functions. For any random variable  with a finite expected value and for any concave function
with a finite expected value and for any concave function  ,
,![E[h(Z)] \leq h[E(Z)]](https://s0.wp.com/latex.php?latex=E%5Bh%28Z%29%5D+%5Cleq+h%5BE%28Z%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.![P[\lim_{n \to \infty} \sup_{x \epsilon \mathbb{R}} |\hat{F}_n(x) - F_X(x)| = 0] = 1.](https://s0.wp.com/latex.php?latex=P%5B%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Csup_%7Bx+%5Cepsilon+%5Cmathbb%7BR%7D%7D+%7C%5Chat%7BF%7D_n%28x%29+-+F_X%28x%29%7C+%3D+0%5D+%3D+1.&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[|X - \mu| \geq k \sigma] \leq 1 \div k^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+1+%5Cdiv+k%5E2&bg=f0f0f0&fg=555555&s=0 "P[|X - \mu| \geq k \sigma] \leq 1 \div k^2")
 is most frequently observed near its expected value,
is most frequently observed near its expected value,  . Remarkably, it quantifies just how often
. Remarkably, it quantifies just how often  standard deviations away from
standard deviations away from  . Notice that this upper bound decreases as
. Notice that this upper bound decreases as  and
and  are finite. (Markov’s inequality
are finite. (Markov’s inequality ![V(X) = E[(X - \mu)^2], \ \text{where} \ \mu = E(X)](https://s0.wp.com/latex.php?latex=V%28X%29+%3D+E%5B%28X+-+%5Cmu%29%5E2%5D%2C+%5C+%5Ctext%7Bwhere%7D+%5C+%5Cmu+%3D+E%28X%29&bg=f0f0f0&fg=555555&s=0&c=20201002) .
. into
into  with another constant,
with another constant,  .
.
![P[(X - \mu)^2 \geq b^2] \leq E[(X - \mu)^2] \div b^2](https://s0.wp.com/latex.php?latex=P%5B%28X+-+%5Cmu%29%5E2+%5Cgeq+b%5E2%5D+%5Cleq+E%5B%28X+-+%5Cmu%29%5E2%5D+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[ (X - \mu) \leq -b \ \ \text{or} \ \ (X - \mu) \geq b] \leq V(X) \div b^2](https://s0.wp.com/latex.php?latex=P%5B+%28X+-+%5Cmu%29+%5Cleq+-b+%5C+%5C+%5Ctext%7Bor%7D+%5C+%5C+%28X+-+%5Cmu%29+%5Cgeq+b%5D+%5Cleq+V%28X%29+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[|X - \mu| \geq b] \leq V(X) \div b^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+b%5D+%5Cleq+V%28X%29+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
 with
with 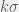 , where
, where  is the standard deviation of
is the standard deviation of 
![P[|X - \mu| \geq k \sigma] \leq V(X) \div k^2 \sigma^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+V%28X%29+%5Cdiv+k%5E2+%5Csigma%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[|X - \mu| \geq k \sigma] \leq 1 \div k^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+1+%5Cdiv+k%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
 where
where 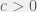 .
. becomes less probable.
becomes less probable. , then
, then ![P[X \geq E(X)] \leq 1](https://s0.wp.com/latex.php?latex=P%5BX+%5Cgeq+E%28X%29%5D+%5Cleq+1&bg=f0f0f0&fg=555555&s=0&c=20201002) ; this is the highest upper bound that
; this is the highest upper bound that  can get. This makes intuitive sense;
can get. This makes intuitive sense;  , then
, then 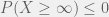 . By Kolmogorov’s axioms of probability, any probability must be inclusively between
. By Kolmogorov’s axioms of probability, any probability must be inclusively between 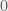 and
and  , so
, so  . This makes intuitive sense; there is no possible way that
. This makes intuitive sense; there is no possible way that 

 ,
, being called the dependent variable and
being called the dependent variable and  being called the independent variable. This terminology holds true for more complicated functions with multiple variables, such as in
being called the independent variable. This terminology holds true for more complicated functions with multiple variables, such as in 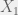 and
and  are independent if their joint distribution is simply a product of their marginal distributions, and they are dependent if otherwise. Thus, the usage of “independent variable” for a regression model with 2 predictors becomes problematic if the model assumes that the predictors are random variables; a random effects model is an example with such an assumption. An obvious question for such models is whether or not the independent variables are independent, which is a rather confusing question with 2 uses of the word “independent”. A better way to phrase that question is whether or not the predictors are independent.
are independent if their joint distribution is simply a product of their marginal distributions, and they are dependent if otherwise. Thus, the usage of “independent variable” for a regression model with 2 predictors becomes problematic if the model assumes that the predictors are random variables; a random effects model is an example with such an assumption. An obvious question for such models is whether or not the independent variables are independent, which is a rather confusing question with 2 uses of the word “independent”. A better way to phrase that question is whether or not the predictors are independent. .
. .
. , are independent and identically distributed,
, are independent and identically distributed, , is approximately normal, and this approximation is better as
, is approximately normal, and this approximation is better as ![h(t) = \lim_{\Delta t \rightarrow 0} [P(t < X \leq t + \Delta t \ | \ X > t) \ \div \ \Delta t]](https://s0.wp.com/latex.php?latex=h%28t%29+%3D+%5Clim_%7B%5CDelta+t+%5Crightarrow+0%7D+%5BP%28t+%3C+X+%5Cleq+t+%2B+%5CDelta+t+%5C+%7C+%5C+X+%3E+t%29+%5C+%5Cdiv+%5C+%5CDelta+t%5D&bg=f0f0f0&fg=555555&s=0 "h(t) = \lim_{\Delta t \rightarrow 0} [P(t < X \leq t + \Delta t \ | \ X > t) \ \div \ \Delta t]") .
.
Recent Comments