A macro to execute PROC TTEST for multiple binary grouping variables in SAS (and sorting t-test statistics by their absolute values)
May 4, 2018 Leave a comment
In SAS, you can perform PROC TTEST for multiple numeric variables in the same procedure. Here is an example using the built-in data set SASHELP.BASEBALL; I will compare the number of at-bats and number of walks between the American League and the National League.
proc ttest
data = sashelp.baseball;
class League;
var nAtBat nBB;
ods select ttests;
run;
Here are the resulting tables.
| Method | Variances | DF | t Value | Pr > |t| |
|---|---|---|---|---|
| Pooled | Equal | 320 | 2.05 | 0.0410 |
| Satterthwaite | Unequal | 313.66 | 2.06 | 0.04 |
| Method | Variances | DF | t Value | Pr > |t| |
|---|---|---|---|---|
| Pooled | Equal | 320 | 0.85 | 0.3940 |
| Satterthwaite | Unequal | 319.53 | 0.86 | 0.3884 |
What if you want to perform PROC TTEST for multiple grouping (a.k.a. classification) variables? You cannot put more than one variable in the CLASS statement, so you would have to run PROC TTEST separately for each binary grouping variable. If you do put LEAGUE and DIVISION in the same CLASS statement, here is the resulting log.
1303 proc ttest 1304 data = sashelp.baseball; 1305 class league division; -------- 22 202 ERROR 22-322: Expecting ;. ERROR 202-322: The option or parameter is not recognized and will be ignored. 1306 var natbat; 1307 ods select ttests; 1308 run;
There is no syntax in PROC TTEST to use multiple grouping variables at the same time, so this tutorial provides a macro to do so. There are several nice features about my macro:
- It allows you to use multiple grouping variables at the same time.
- It sorts the t-test statistics by their absolute values within each grouping variable.
- It shows the name of each continuous variable in the output table, unlike the above output.
Here is its basic skeleton.
 and
and  , the correlation coefficient between them is defined as their covariance scaled by the product of their standard deviations. Algebraically, this can be expressed as
, the correlation coefficient between them is defined as their covariance scaled by the product of their standard deviations. Algebraically, this can be expressed as![\rho_{X, Y} = \frac{Cov(X, Y)}{\sigma_X \sigma_Y} = \frac{E[(X - \mu_X)(Y - \mu_Y)]}{\sigma_X \sigma_Y}](https://s0.wp.com/latex.php?latex=%5Crho_%7BX%2C+Y%7D+%3D+%5Cfrac%7BCov%28X%2C+Y%29%7D%7B%5Csigma_X+%5Csigma_Y%7D+%3D+%5Cfrac%7BE%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D%7D%7B%5Csigma_X+%5Csigma_Y%7D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.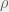 is the Pearson correlation coefficient, which is defined as the sample covariance between
is the Pearson correlation coefficient, which is defined as the sample covariance between 
 .
.
 is the sample standard deviation and
is the sample standard deviation and  is the sample mean.
is the sample mean.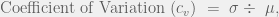
 is the random variable’s standard deviation and
is the random variable’s standard deviation and  is the random variable’s expected value.
is the random variable’s expected value. positive real numbers
positive real numbers  is defined as
is defined as .
.












Recent Comments