Validation is a good way to assess the predictive accuracy of a supervised learning algorithm, and the rule of thumb of using 70% of the data for training and 30% of the data for validation generally works well. However, what if the data set is not very large, and the small amount of data for training results in high sampling error? A good way to overcome this problem is K-fold cross-validation.
Cross-validation is best defined by describing its steps:
For each model under consideration,
- Divide the data set into K partitions.
- Designate the first partition as the validation set and designate the other partitions as the training set.
- Use training set to train the algorithm.
- Use the validation set to assess the predictive accuracy of the algorithm; the common measure of predictive accuracy is mean squared error.
- Repeat Steps 2-4 for the second partition, third partition, … , the (K-1)th partition, and the Kth partition. (Essentially, rotate the designation of validation set through every partition.)
- Calculate the average of the mean squared error from all K validations.
Compare the average mean squared errors of all models and pick the one with the smallest average mean squared error as the best model. Test all models on a separate data set (called the test set) to assess their predictive accuracies on new, fresh data.
If there are N data in the data set, and K = N, then this type of K-fold cross-validation has a special name: leave-one-out cross-validation (LOOCV).
There some trade-offs between a large and a small K. The estimator for the prediction error from a larger K results in
- less bias because of more data being used for training
- higher variance because of the higher similarity and lower diversity between the training sets
- slower computation because of more data being used for training
In The Elements of Statistical Learning (2009 Edition, Chapter 7, Page 241-243), Hastie, Tibshirani and Friedman recommend 5 or 10 for K.
![P[|X - \mu| \geq k \sigma] \leq 1 \div k^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+1+%5Cdiv+k%5E2&bg=f0f0f0&fg=555555&s=0 "P[|X - \mu| \geq k \sigma] \leq 1 \div k^2")
 is most frequently observed near its expected value,
is most frequently observed near its expected value,  . Remarkably, it quantifies just how often
. Remarkably, it quantifies just how often  standard deviations away from
standard deviations away from  . Notice that this upper bound decreases as
. Notice that this upper bound decreases as  and
and  are finite. (Markov’s inequality
are finite. (Markov’s inequality ![V(X) = E[(X - \mu)^2], \ \text{where} \ \mu = E(X)](https://s0.wp.com/latex.php?latex=V%28X%29+%3D+E%5B%28X+-+%5Cmu%29%5E2%5D%2C+%5C+%5Ctext%7Bwhere%7D+%5C+%5Cmu+%3D+E%28X%29&bg=f0f0f0&fg=555555&s=0&c=20201002) .
. into
into  with another constant,
with another constant,  .
.
![P[(X - \mu)^2 \geq b^2] \leq E[(X - \mu)^2] \div b^2](https://s0.wp.com/latex.php?latex=P%5B%28X+-+%5Cmu%29%5E2+%5Cgeq+b%5E2%5D+%5Cleq+E%5B%28X+-+%5Cmu%29%5E2%5D+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[ (X - \mu) \leq -b \ \ \text{or} \ \ (X - \mu) \geq b] \leq V(X) \div b^2](https://s0.wp.com/latex.php?latex=P%5B+%28X+-+%5Cmu%29+%5Cleq+-b+%5C+%5C+%5Ctext%7Bor%7D+%5C+%5C+%28X+-+%5Cmu%29+%5Cgeq+b%5D+%5Cleq+V%28X%29+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[|X - \mu| \geq b] \leq V(X) \div b^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+b%5D+%5Cleq+V%28X%29+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
 with
with 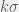 , where
, where  is the standard deviation of
is the standard deviation of 
![P[|X - \mu| \geq k \sigma] \leq V(X) \div k^2 \sigma^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+V%28X%29+%5Cdiv+k%5E2+%5Csigma%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[|X - \mu| \geq k \sigma] \leq 1 \div k^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+1+%5Cdiv+k%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)



Recent Comments