The word “experiment” can mean many different things in various contexts. In science and statistics, it has a very particular and subtle definition, one that is not immediately familiar to many people who work outside of the field of experimental design. This is the first of a series of blog posts to clarify what an experiment is, how it is conducted, and why it is so central to science and statistics.
Experiment: A procedure to determine the causal relationship between 2 variables – an explanatory variable and a response variable. The value of the explanatory variable is changed, and the value of the response variable is observed for each value of the explantory variable.
- An experiment can have 2 or more explanatory variables and 2 or more response variables.
- In my experience, I find that most experiments have 1 response variable, but many experiments have 2 or more explanatory variables. The interactions between the multiple explanatory variables are often of interest.
- All other variables are held constant in this process to avoid confounding.
Explanatory Variable or Factor: The variable whose values are set by the experimenter. This variable is the cause in the hypothesis. (*Many people call this the independent variable. I discourage this usage, because “independent” means something very different in statistics.)
Response Variable: The variable whose values are observed by the experimenter as the explanatory variable’s value is changed. This variable is the effect in the hypothesis. (*Many people call this the dependent variable. Further to my previous point about “independent variables”, dependence means something very different in statistics, and I discourage using this usage.)
Factor Level: Each possible value of the factor (explanatory variable). A factor must have at least 2 levels.
Treatment: Each possible combination of factor levels.
- If the experiment has only 1 explanatory variable, then each treatment is simply each factor level.
- If the experiment has 2 explanatory variables, X and Y, then each treatment is a combination of 1 factor level from X and 1 factor level from Y. Such combining of factor levels generalizes to experiments with more than 2 explanatory variables.
Experimental Unit: The object on which a treatment is applied. This can be anything – person, group of people, animal, plant, chemical, guitar, baseball, etc.




 notation; unfortunately, this notation is not clearly explained in most textbooks or web sites about
notation; unfortunately, this notation is not clearly explained in most textbooks or web sites about  is the number of levels in each factor; note that the
is the number of levels in each factor; note that the  and
and 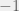 .
.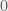 , and
, and  is the number of factors in the experiment
is the number of factors in the experiment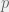 is the number of times that the full factorial design is fractionated by
is the number of times that the full factorial design is fractionated by 
 .
. ). Thus,
). Thus, , then the fraction of treatments that is used is
, then the fraction of treatments that is used is  .
. , then the fraction of treatments that is used is
, then the fraction of treatments that is used is  .
. design is often called a half-fraction design.
design is often called a half-fraction design. design is often called a quarter-fraction design.
design is often called a quarter-fraction design. , then
, then design uses one-third of all possible treatments.
design uses one-third of all possible treatments. design uses one-ninth of all possible treatments.
design uses one-ninth of all possible treatments.

 is the response and
is the response and 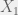 and
and  are the 2 predictors, then an additive linear model for the relationship between the response and the predictors is
are the 2 predictors, then an additive linear model for the relationship between the response and the predictors is

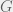 factors and the response, where
factors and the response, where 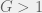 . On first instinct, you may be tempted to conduct
. On first instinct, you may be tempted to conduct 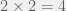 treatments, each being a combination of 1 level from the first factor and 1 level from the second factor. Since this is a full factorial design, experimental units are independently assigned to all treatments. The 2-factor ANOVA model is commonly used to analyze data from such designs.
treatments, each being a combination of 1 level from the first factor and 1 level from the second factor. Since this is a full factorial design, experimental units are independently assigned to all treatments. The 2-factor ANOVA model is commonly used to analyze data from such designs. experimental units into
experimental units into  pairs. Within each pair (i.e. each block), the
pairs. Within each pair (i.e. each block), the 

Recent Comments