Validation is a good way to assess the predictive accuracy of a supervised learning algorithm, and the rule of thumb of using 70% of the data for training and 30% of the data for validation generally works well. However, what if the data set is not very large, and the small amount of data for training results in high sampling error? A good way to overcome this problem is K-fold cross-validation.
Cross-validation is best defined by describing its steps:
For each model under consideration,
- Divide the data set into K partitions.
- Designate the first partition as the validation set and designate the other partitions as the training set.
- Use training set to train the algorithm.
- Use the validation set to assess the predictive accuracy of the algorithm; the common measure of predictive accuracy is mean squared error.
- Repeat Steps 2-4 for the second partition, third partition, … , the (K-1)th partition, and the Kth partition. (Essentially, rotate the designation of validation set through every partition.)
- Calculate the average of the mean squared error from all K validations.
Compare the average mean squared errors of all models and pick the one with the smallest average mean squared error as the best model. Test all models on a separate data set (called the test set) to assess their predictive accuracies on new, fresh data.
If there are N data in the data set, and K = N, then this type of K-fold cross-validation has a special name: leave-one-out cross-validation (LOOCV).
There some trade-offs between a large and a small K. The estimator for the prediction error from a larger K results in
- less bias because of more data being used for training
- higher variance because of the higher similarity and lower diversity between the training sets
- slower computation because of more data being used for training
In The Elements of Statistical Learning (2009 Edition, Chapter 7, Page 241-243), Hastie, Tibshirani and Friedman recommend 5 or 10 for K.





 .
. is the best that we can use for such guessing. If we do have predictors, then we aim to develop a model (i.e. the binary classifier) that uses the information from the predictors to make predictions that are better than random guessing. Thus, a minimum standard of a binary classifier is having an ROC curve that is higher than the line of no discrimination. (By “higher“, I mean that, for a given value of
is the best that we can use for such guessing. If we do have predictors, then we aim to develop a model (i.e. the binary classifier) that uses the information from the predictors to make predictions that are better than random guessing. Thus, a minimum standard of a binary classifier is having an ROC curve that is higher than the line of no discrimination. (By “higher“, I mean that, for a given value of  and the covariates
and the covariates  . A logistic regression model takes the covariates as inputs and returns
. A logistic regression model takes the covariates as inputs and returns  . You as the user of the model must decide above which value of
. You as the user of the model must decide above which value of  ; this value is the discrimination threshold. A common threshold is
; this value is the discrimination threshold. A common threshold is  .
.

 ,
, . In other words,
. In other words,  is the design matrix, and the element in row
is the design matrix, and the element in row  and column
and column  of this design matrix is the
of this design matrix is the  predictor being evaluated in the
predictor being evaluated in the  basis function. (In this case, there is 1 predictor per datum.)
basis function. (In this case, there is 1 predictor per datum.)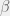 , can be estimated by
, can be estimated by .
. , but
, but  was obtained, I encourage you to review least-squares estimation and the derivation of the estimator of the coefficient vector in linear regression.
was obtained, I encourage you to review least-squares estimation and the derivation of the estimator of the coefficient vector in linear regression.![\phi_j(x) = exp[-(x - \mu_j)^2 \div 2\sigma^2]](https://s0.wp.com/latex.php?latex=%5Cphi_j%28x%29+%3D+exp%5B-%28x+-+%5Cmu_j%29%5E2+%5Cdiv+2%5Csigma%5E2%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)
 in this basis function determines the spacing between the different basis functions that combine to form the model.
in this basis function determines the spacing between the different basis functions that combine to form the model. ; the scaling factor ensures that the normal PDF integrates to 1 over its support set. In a linear basis function model, the regression coefficients are the weights for the basis functions, and these weights will scale Gaussian basis functions to fit the data that are local to
; the scaling factor ensures that the normal PDF integrates to 1 over its support set. In a linear basis function model, the regression coefficients are the weights for the basis functions, and these weights will scale Gaussian basis functions to fit the data that are local to 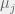 . Thus, there is no need to include that scaling factor of
. Thus, there is no need to include that scaling factor of 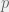 inputs (
inputs ( ) to predict a continuous target
) to predict a continuous target  basis functions.
basis functions.
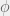 ) is chosen to suitably model the non-linearity in the relationship between the inputs and the target. It also needs to be chosen so that the computation is efficient. I will discuss variations of linear basis function models in a later
) is chosen to suitably model the non-linearity in the relationship between the inputs and the target. It also needs to be chosen so that the computation is efficient. I will discuss variations of linear basis function models in a later  , predicts the change in the target,
, predicts the change in the target, 
Recent Comments