Suppose that you invested in a stock 3 years ago, and the annual rates of return for each of the 3 years were
- 5% in the 1st year
- 10% in the 2nd year
- 15% in the 3rd year
What is the average rate of return in those 3 years?
It’s tempting to use the arithmetic mean, since we are so used to using it when trying to estimate the “centre” of our data. However, the arithmetic mean is not appropriate in this case, because the annual rate of return implies a multiplicative growth of your investment by a factor of  , where
, where  is the rate of return in each year. In contrast, the arithmetic mean is appropriate for quantities that are additive in nature; for example, your average annual salary from the past 3 years is the sum of last 3 annual salaries divided by 3.
is the rate of return in each year. In contrast, the arithmetic mean is appropriate for quantities that are additive in nature; for example, your average annual salary from the past 3 years is the sum of last 3 annual salaries divided by 3.
If the arithmetic mean is not appropriate, then what can we use instead? Our saviour is the geometric mean, 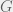 . The average factor of growth from the 3 years is
. The average factor of growth from the 3 years is
![G = [(1 + r_1)(1 + r_2) ... (1 + r_n)]^{1/n}](https://s0.wp.com/latex.php?latex=G+%3D+%5B%281+%2B+r_1%29%281+%2B+r_2%29+...+%281+%2B+r_n%29%5D%5E%7B1%2Fn%7D&bg=f0f0f0&fg=555555&s=0&c=20201002) ,
,
where  is the rate of return in year
is the rate of return in year  ,
,  . The average annual rate of return is
. The average annual rate of return is  . Note that the geometric mean is NOT applied to the annual rates of return, but the annual factors of growth.
. Note that the geometric mean is NOT applied to the annual rates of return, but the annual factors of growth.
Returning to our example, our average factor of growth is
![G = [(1 + 0.05) \times (1 + 0.10) \times (1 + 0.15)]^{1/3} = 1.099242](https://s0.wp.com/latex.php?latex=G+%3D+%5B%281+%2B+0.05%29+%5Ctimes+%281+%2B+0.10%29+%5Ctimes+%281+%2B+0.15%29%5D%5E%7B1%2F3%7D+%3D+1.099242&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.
Thus, our annual rate of return is  .
.
Here is a good way to think about the difference between the arithmetic mean and the geometric mean. Suppose that there are 2 sets of numbers.
- The first set,
 , consists of your data
, consists of your data  , and this set has a sample size of
, and this set has a sample size of  .
.
- The second,
 , set also has a sample size of , but all values are the same – let’s call this common value
, set also has a sample size of , but all values are the same – let’s call this common value  .
.
- What number must be such that the sums in and are equal? This value of is the arithmetic mean of the first set.
- What number must be such that the products in and are equal? This value of is the geometric mean of the first set.
Note that the geometric means is only applicable to positive numbers.
 is an irrational number. He then talked about the concept of bijections while defining countability, and he showed that rational numbers are countable.
is an irrational number. He then talked about the concept of bijections while defining countability, and he showed that rational numbers are countable.
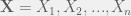
 . Let
. Let 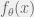 be the probability density function (PDF) or probability mass function (PMF) for
be the probability density function (PDF) or probability mass function (PMF) for  .
.
 .
. is a complete and minimal sufficient statistic, then
is a complete and minimal sufficient statistic, then 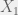 and
and  , from the normal distribution
, from the normal distribution  , where
, where  is unknown. Then the statistic
is unknown. Then the statistic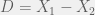
 .
. does not depend on
does not depend on 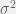 is unknown, then
is unknown, then  is any other sufficient statistic, then there exists a function
is any other sufficient statistic, then there exists a function 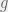 such that
such that![T(\textbf{X}) = g[U(\textbf{X})].](https://s0.wp.com/latex.php?latex=T%28%5Ctextbf%7BX%7D%29+%3D+g%5BU%28%5Ctextbf%7BX%7D%29%5D.&bg=f0f0f0&fg=555555&s=0&c=20201002)
 such that
such that![T(\textbf{X}) = h[U(\textbf{X})],](https://s0.wp.com/latex.php?latex=T%28%5Ctextbf%7BX%7D%29+%3D+h%5BU%28%5Ctextbf%7BX%7D%29%5D%2C&bg=f0f0f0&fg=555555&s=0&c=20201002)
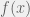 that is continuous on the interval
that is continuous on the interval ![[x_1, x_2]](https://s0.wp.com/latex.php?latex=%5Bx_1%2C+x_2%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) , where
, where 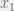 and
and 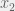 are any 2 points in the domain of
are any 2 points in the domain of 
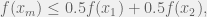
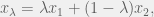 where
where 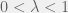 .
.

 with a finite expected value and for any convex function
with a finite expected value and for any convex function  ,
,![E[g(Y)] \geq g[E(Y)]](https://s0.wp.com/latex.php?latex=E%5Bg%28Y%29%5D+%5Cgeq+g%5BE%28Y%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.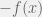 is convex. Thus, Jensen’s inequality can also be stated for concave functions. For any random variable
is convex. Thus, Jensen’s inequality can also be stated for concave functions. For any random variable  with a finite expected value and for any concave function
with a finite expected value and for any concave function  ,
,![E[h(Z)] \leq h[E(Z)]](https://s0.wp.com/latex.php?latex=E%5Bh%28Z%29%5D+%5Cleq+h%5BE%28Z%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.![P[\lim_{n \to \infty} \sup_{x \epsilon \mathbb{R}} |\hat{F}_n(x) - F_X(x)| = 0] = 1.](https://s0.wp.com/latex.php?latex=P%5B%5Clim_%7Bn+%5Cto+%5Cinfty%7D+%5Csup_%7Bx+%5Cepsilon+%5Cmathbb%7BR%7D%7D+%7C%5Chat%7BF%7D_n%28x%29+-+F_X%28x%29%7C+%3D+0%5D+%3D+1.&bg=f0f0f0&fg=555555&s=0&c=20201002)
 is just an expected value of a function of
is just an expected value of a function of ![V(X) = E[(X - \mu)^2], \ \text{where} \ \mu = E(X)](https://s0.wp.com/latex.php?latex=V%28X%29+%3D+E%5B%28X+-+%5Cmu%29%5E2%5D%2C+%5C+%5Ctext%7Bwhere%7D+%5C+%5Cmu+%3D+E%28X%29&bg=f0f0f0&fg=555555&s=0&c=20201002) .
. into
into  with another constant,
with another constant,  .
.
![P[(X - \mu)^2 \geq b^2] \leq E[(X - \mu)^2] \div b^2](https://s0.wp.com/latex.php?latex=P%5B%28X+-+%5Cmu%29%5E2+%5Cgeq+b%5E2%5D+%5Cleq+E%5B%28X+-+%5Cmu%29%5E2%5D+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[ (X - \mu) \leq -b \ \ \text{or} \ \ (X - \mu) \geq b] \leq V(X) \div b^2](https://s0.wp.com/latex.php?latex=P%5B+%28X+-+%5Cmu%29+%5Cleq+-b+%5C+%5C+%5Ctext%7Bor%7D+%5C+%5C+%28X+-+%5Cmu%29+%5Cgeq+b%5D+%5Cleq+V%28X%29+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[|X - \mu| \geq b] \leq V(X) \div b^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+b%5D+%5Cleq+V%28X%29+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
 with
with 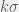 , where
, where  is the standard deviation of
is the standard deviation of 
![P[|X - \mu| \geq k \sigma] \leq V(X) \div k^2 \sigma^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+V%28X%29+%5Cdiv+k%5E2+%5Csigma%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[|X - \mu| \geq k \sigma] \leq 1 \div k^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+1+%5Cdiv+k%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)

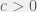 .
.
Recent Comments