I will attend the following seminar by Thomas Levi in the next R/Machine Learning/Data Science Meetup in Vancouver on Wednesday, June 25. If you will also attend this event, please come up and say “Hello”! I would be glad to meet you!

To register, sign up for an account on Meetup, and RSVP in the R Users Group, the Machine Learning group or the Data Science group.
Title: NLP to Find User Archetypes for Search & Matching
Speaker: Thomas Levi, Plenty of Fish
Location: HootSuite, 5 East 8th Avenue, Vancouver, BC
Time and Date: 6-8 pm, Wednesday, June 25, 2014
Abstract
As the world’s largest free dating site, Plenty Of Fish would like to be able to match with and allow users to search for people with similar interests. However, we allow our users to enter their interests as free text on their profiles. This presents a difficult problem in clustering, search and machine learning if we want to move beyond simple ‘exact match’ solutions to a deeper archetypal user profiling and thematic search system. Some of the common issues that arise are misspellings, synonyms (e.g. biking, cycling and bicycling) and similar interests (e.g. snowboarding and skiing) on a several million user scale. In this talk I will demonstrate how we built a system utilizing topic modelling with Latent Dirichlet Allocation (LDA) on a several hundred thousand word vocabulary over ten million+ North American users and explore its applications at POF.
Bio
Thomas Levi started out with a doctorate in Theoretical Physics and String Theory from the University of Pennsylvania in 2006. His post-doctoral studies in cosmology and string theory, where he wrote 19 papers garnering 650+ citations, then took him to NYU and finally UBC. In 2012, he decided to move into industry, and took on the role of Senior Data Scientist at POF. Thomas has been involved in diverse projects such as behaviour analysis, social network analysis, scam detection, Bot detection, matching algorithms, topic modelling and semantic analysis.
Schedule
• 6:00PM Doors are open, feel free to mingle
• 6:30 Presentations start
• 8:00 Off to a nearby watering hole (Mr. Brownstone?) for a pint, food, and/or breakout discussions

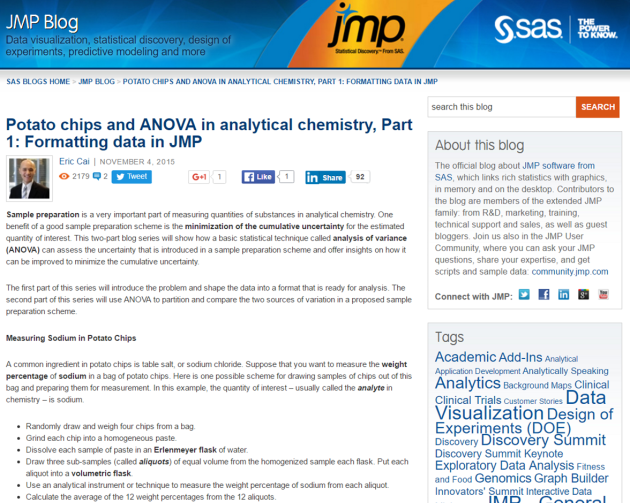

![P[(\text{Winner}_1 = \text{Home Team}_1) \cap (\text{Winner}_2 = \text{Home Team}_2) \cap \ldots \cap (\text{Winner}_{15}= \text{Home Team}_{15})]](https://s0.wp.com/latex.php?latex=P%5B%28%5Ctext%7BWinner%7D_1+%3D+%5Ctext%7BHome+Team%7D_1%29+%5Ccap+%28%5Ctext%7BWinner%7D_2+%3D+%5Ctext%7BHome+Team%7D_2%29+%5Ccap+%5Cldots+%5Ccap+%28%5Ctext%7BWinner%7D_%7B15%7D%3D+%5Ctext%7BHome+Team%7D_%7B15%7D%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)

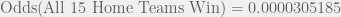




{kind=link}
Recent Comments