In my recent lesson on controlling for confounders in experimental design, the control group was described as one that received a neutral or standard treatment, and the standard treatment may simply be nothing. This is a negative control group. Not all experiments require a negative control group; some experiments instead have positive control group.
A positive control group is a group of experimental units that receive a treatment that is known to cause an effect on the response. Such a causal relationship would have been previously established, and its inclusion in the experiment allows a new treatment to be compared to this existing treatment. Again, both the positive control group and the experimental group experience the same experimental procedures and conditions except for the treatment. The existing treatment with the known effect on the response is applied to the positive control group, and the new treatment with the unknown effect on the response is applied to the experimental group. If the new treatment has a causal relationship with the response, both the positive control group and the experimental group should have the same responses. (This assumes, of course, that the response can only be changed in 1 direction. If the response can increase or decrease in value (or, more generally, change in more than 1 way), then it is possible for the positive control group and the experimental group to have the different responses.
In short, in an experiment with a positive control group, an existing treatment is known to “work”, and the new treatment is being tested to see if it can “work” just as well or even better. Experiments to test for the effectiveness of a new medical therapies or a disease detector often have positive controls; there are existing therapies or detectors that work well, and the new therapy or detector is being evaluated for its effectiveness.
Experiments with positive controls are useful for ensuring that the experimental procedures and conditions proceed as planned. If the positive control does not show the expected response, then something is wrong with the experimental procedures or conditions, and any “good” result from the new treatment should be considered with skepticism.
 .
. , for that event is defined as
, for that event is defined as![h(t) = \lim_{\Delta t \rightarrow 0} [P(t < X \leq t + \Delta t \ | \ X > t) \ \div \ \Delta t]](https://s0.wp.com/latex.php?latex=h%28t%29+%3D+%5Clim_%7B%5CDelta+t+%5Crightarrow+0%7D+%5BP%28t+%3C+X+%5Cleq+t+%2B+%5CDelta+t+%5C+%7C+%5C+X+%3E+t%29+%5C+%5Cdiv+%5C+%5CDelta+t%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) ,
,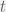 is the time,
is the time, is the time of the occurrence of the event.
is the time of the occurrence of the event.
 to indicate that this is heat transferred under constant volume. In this case, the change in enthalpy is the same as the change in internal energy.
to indicate that this is heat transferred under constant volume. In this case, the change in enthalpy is the same as the change in internal energy.
 to indicate that this is heat transferred under constant pressure. Thus, as the gas forms inside the cylinder, the piston pushes against the constant pressure that the atmosphere exerts on it. The total energy released by the chemical reaction allows some energy to be used for the pressure-volume work, with the remaining energy being released via heat. (Recall that these are the 2 ways for internal energy to be changed according to the
to indicate that this is heat transferred under constant pressure. Thus, as the gas forms inside the cylinder, the piston pushes against the constant pressure that the atmosphere exerts on it. The total energy released by the chemical reaction allows some energy to be used for the pressure-volume work, with the remaining energy being released via heat. (Recall that these are the 2 ways for internal energy to be changed according to the 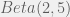 distribution actually integrates to 1 over its support set. This post follows from my previous post on
distribution actually integrates to 1 over its support set. This post follows from my previous post on 
 smaller intervals of equal lengths, and
smaller intervals of equal lengths, and  .
. .
.







Recent Comments