Introduction
This blog post will focus on some conceptual foundations of simple linear regression, a very common technique in statistics and a precursor for understanding multiple linear regression. I will expose and clarify many nuances and subtleties that I did not fully absorb until my Master’s degree in statistics at the University of Toronto.
What is Simple Linear Regression?
Simple linear regression is a predictive model that uses a predictor variable (x) to predict a continuous target variable (Y). It is a formal and rigorous way to express 2 fundamental components of a statistical predictive model.
1) For each value of x, there is a probability distribution of Y.
2) The means of the probability distributions for all values of Y vary with x in a systematic way.
Mathematically, the first component is reflected in a random error variable, and the second component is reflected in the constant that expresses the linear relationship between x and Y. These two components add together to give the following mathematical model.



The last mathematical expression states that two different error terms are statistically independent.
Essentially, this model captures the tendency for Y to vary systematically with x. The systematic part is the constant term,  . The tendency (rather than a direct relation) is reflected in the probability distribution of the error component.
. The tendency (rather than a direct relation) is reflected in the probability distribution of the error component.
Note that I capitalized the target Y because it is a random variable. (It is a linear combination of the random error, so it is also a random variable.) I used lower-case for the predictor because it is a constant in the model.

What are the Assumptions of Simple Linear Regression?
1) The predictor variable is a fixed constant with no random variation. If you want to model the predictor as a random variable, use the errors-in-variables model (a.k.a. measurement errors model).
2) The target variable is a linear combination of the regression coefficients and the predictor.
3) The variance of the random error component is constant. This assumptions is called homoscedasticity.
4) The random errors are independent of each other.
5) The regression coefficients are constants. If you want to model the regression coefficients as random variables, use the random effects model. If you want to include both fixed and random coefficients in your model, use the mixed effects model. The documentation for PROX MIXED in SAS/STAT has a nice explanation of mixed effects model. I also recommend the documentation for PROC GLM for more about the random effects model.
***6) The random errors are normally distributed with an expected value of 0 and a variance of  . As Assumption #3 states, this variance is constant for all
. As Assumption #3 states, this variance is constant for all  .
.
***This last assumption is not needed for the least-squares estimation of the regression coefficients. However, it is needed for conducting statistical inference for the regression coefficients, such as testing hypotheses and constructing confidence intervals.
Important Clarifications about the Terminology
Let me clarify some common confusion about the 2 key terms in the name “simple linear regression”.
– It is called “simple” because it uses only one predictor, whereas multiple linear regression uses multiple predictors. While it is relatively simple to understand, and while it is a simple model compared to other predictive models, there are many concepts and nuances behind linear regression that still makes it difficult to understand for many people. (I hope that this blog post will make it easier to understand this model!)
– It is called “linear” because the target variable is linear with respect to the parameters  and
and  (the regression coefficients), not because it is linear with respect to the predictor; this is a very common misunderstanding, and I did not learn this until the second course in which I learned about linear regression. This is more than just a naming custom; it implies that the regression coefficients can be estimated using linear algebra, which has many benefits that will be described in a later post.
(the regression coefficients), not because it is linear with respect to the predictor; this is a very common misunderstanding, and I did not learn this until the second course in which I learned about linear regression. This is more than just a naming custom; it implies that the regression coefficients can be estimated using linear algebra, which has many benefits that will be described in a later post.
Simple linear regression does assume that the target variable has a linear relationship with the predictor variable. However, if it doesn’t, it can often be resolved – the predictor and/or the target can often be transformed to make the relationship linear. If, however, the target variable cannot be written as a linear combination of the parameters and , then the model is no longer linear regression, even if the target is linear with respect to the predictor.
How are the Regression Coefficients Estimated?
The regression coefficients are estimated by finding values of and that minimize the sum of the squares of the deviations from the regression line to the data. My first linear regression textbook, “Applied Linear Statistical Models” by Kutner, Nachtsheim, Neter, and Li uses the letter “Q” to denote this quantity. This is called the method of least squares. The word “minimize” should trigger finding the global optimizers using differential calculus.

Differentiate Q with respect to  and
and 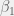 ; set the 2 derivatives to zero to get the normal equations. The estimates are obtained by solving this system of 2 equations.
; set the 2 derivatives to zero to get the normal equations. The estimates are obtained by solving this system of 2 equations.
Why is the Least-Squares Method Used to Estimate the Regression Coefficients?
A natural question arises: Why minimize the sum of the squares of the errors? Why not minimize some other measure of the distances from the regression line to the data, like the sum of the absolute values of the errors?

The answer lies within the Gauss-Markov theorem, which guarantees some very attractive properties for the least-squares estimators of the regression coefficients:
– these estimators are unbiased
– out of all linear unbiased estimators, the least-squares estimators have the minimum variance
Thus, the least-squares estimators are both accurate and very precise.
Note that the Gauss-Markov theorem holds without Assumption #6 above, which states that the errors have a normal distribution with an expected value of zero and a variance of .


![\rho_{X, Y} = \frac{Cov(X, Y)}{\sigma_X \sigma_Y} = \frac{E[(X - \mu_X)(Y - \mu_Y)]}{\sigma_X \sigma_Y}](https://s0.wp.com/latex.php?latex=%5Crho_%7BX%2C+Y%7D+%3D+%5Cfrac%7BCov%28X%2C+Y%29%7D%7B%5Csigma_X+%5Csigma_Y%7D+%3D+%5Cfrac%7BE%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D%7D%7B%5Csigma_X+%5Csigma_Y%7D&bg=f0f0f0&fg=555555&s=0&c=20201002)
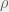


 -order polynomial relationship between the response variable
-order polynomial relationship between the response variable  .
.
 .
.
 and
and  . (Admittedly, if the interpretation of the regression coefficient is important, then such interpretation becomes more difficult with this transformation. However, if prediction of the response is the key goal, then such interpretation is not necessary, and this is not a problem.) The important point is that the estimation of the regression coefficients can still be done by linear algebra after the transformation of the explanatory variable.
. (Admittedly, if the interpretation of the regression coefficient is important, then such interpretation becomes more difficult with this transformation. However, if prediction of the response is the key goal, then such interpretation is not necessary, and this is not a problem.) The important point is that the estimation of the regression coefficients can still be done by linear algebra after the transformation of the explanatory variable.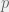 inputs (
inputs ( ) to predict a continuous target
) to predict a continuous target  basis functions.
basis functions.
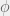 ) is chosen to suitably model the non-linearity in the relationship between the inputs and the target. It also needs to be chosen so that the computation is efficient. I will discuss variations of linear basis function models in a later
) is chosen to suitably model the non-linearity in the relationship between the inputs and the target. It also needs to be chosen so that the computation is efficient. I will discuss variations of linear basis function models in a later 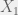 and
and  are the 2 predictors, then an additive linear model for the relationship between the response and the predictors is
are the 2 predictors, then an additive linear model for the relationship between the response and the predictors is

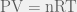 , is a very simple yet useful relationship that describes the behaviours of many
, is a very simple yet useful relationship that describes the behaviours of many 






{kind=link}
{kind=link}
{kind=link}
Recent Comments