A macro to automate the creation of indicator variables in SAS
April 25, 2018 Leave a comment
In a recent blog post, I introduced an easy and efficient way to create indicator variables from categorical variables in SAS. This method pretends to run logistic regression, but it really is using PROC LOGISTIC to get the design matrix based on dummy-variable coding. I shared SAS code for how to do so, step-by-step.
I write this follow-up post to provide a macro that you can use to execute all of those steps in one line. If you have not read my previous post on this topic, then I strongly encourage you to do that first. Don’t use this macro blindly.
Here is the macro. The key steps are
- Run PROC LOGISTIC to get the design matrix (which has the indicator variables)
- Merge the original data with the newly created indicator variables
- Delete the “INDICATORS” data set, which was created in an intermediate step
%macro create_indicators(input_data, target, covariates, output_data);
proc logistic
data = &input_data
noprint
outdesign = indicators;
class &covariates / param = glm;
model &target = &covariates;
run;
data &output_data;
merge &input_data
indicators (drop = Intercept &target);
run;
proc datasets
library = work
noprint;
delete indicators;
run;
%mend;
I will use the built-in data set SASHELP.CARS to illustrate the use of my macro. As you can see, my macro can accept multiple categorical variables as inputs for creating indicator variables. I will do that here for the variables TYPE, MAKE, and ORIGIN.

![P[(\text{Winner}_1 = \text{Home Team}_1) \cap (\text{Winner}_2 = \text{Home Team}_2) \cap \ldots \cap (\text{Winner}_{15}= \text{Home Team}_{15})]](https://s0.wp.com/latex.php?latex=P%5B%28%5Ctext%7BWinner%7D_1+%3D+%5Ctext%7BHome+Team%7D_1%29+%5Ccap+%28%5Ctext%7BWinner%7D_2+%3D+%5Ctext%7BHome+Team%7D_2%29+%5Ccap+%5Cldots+%5Ccap+%28%5Ctext%7BWinner%7D_%7B15%7D%3D+%5Ctext%7BHome+Team%7D_%7B15%7D%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002)
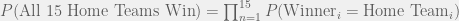
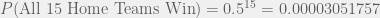
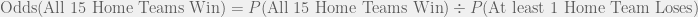

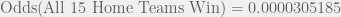
 and
and  , the chi-squared test of independence determines whether or not there exists a statistical dependence between them. Formally, it is a hypothesis test with the following null and alternative hypotheses:
, the chi-squared test of independence determines whether or not there exists a statistical dependence between them. Formally, it is a hypothesis test with the following null and alternative hypotheses:



Recent Comments