Store multiple strings of text as a macro variable in SAS with PROC SQL and the INTO statement
September 8, 2017 Leave a comment
I often need to work with many variables at a time in SAS, but I don’t like to type all of their names manually – not only is it messy to read, it also induces errors in transcription, even when copying and pasting. I recently learned of an elegant and efficient way to store multiple variable names into a macro variable that overcomes those problems. This technique uses the INTO statement in PROC SQL.
To illustrate how this storage method can be applied in a practical context, suppose that we want to determine the factors that contribute to a baseball player’s salary in the built-in SASHELP.BASEBALL data set. I will consider all continuous variables other than “Salary” and “logSalary”, but I don’t want to write them explicitly in any programming statements. To do this, I first obtain the variable names and types of a data set using PROC CONTENTS.
* create a data set of the variable names;
proc contents
data = sashelp.baseball
noprint
out = bvars (keep = name type);
run;
 and
and  , the correlation coefficient between them is defined as their covariance scaled by the product of their standard deviations. Algebraically, this can be expressed as
, the correlation coefficient between them is defined as their covariance scaled by the product of their standard deviations. Algebraically, this can be expressed as![\rho_{X, Y} = \frac{Cov(X, Y)}{\sigma_X \sigma_Y} = \frac{E[(X - \mu_X)(Y - \mu_Y)]}{\sigma_X \sigma_Y}](https://s0.wp.com/latex.php?latex=%5Crho_%7BX%2C+Y%7D+%3D+%5Cfrac%7BCov%28X%2C+Y%29%7D%7B%5Csigma_X+%5Csigma_Y%7D+%3D+%5Cfrac%7BE%5B%28X+-+%5Cmu_X%29%28Y+-+%5Cmu_Y%29%5D%7D%7B%5Csigma_X+%5Csigma_Y%7D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.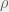 is the Pearson correlation coefficient, which is defined as the sample covariance between
is the Pearson correlation coefficient, which is defined as the sample covariance between 
 .
.

Recent Comments