Applied Statistics Lesson of the Day – Polynomial Regression is Actually Just Linear Regression
June 19, 2014 Leave a comment
Continuing from my previous Statistics Lesson of the Day on what “linear” really means in “linear regression”, I want to highlight a common example involving this nomenclature that can mislead non-statisticians. Polynomial regression is a commonly used multiple regression technique; it models the systematic component of the regression model as a 



However, this model is still a linear regression model, because the response variable is still a linear combination of the regression coefficients. The regression coefficients would still be estimated using linear algebra through the method of least squares.
Remember: the “linear” in linear regression refers to the linearity between the response variable and the regression coefficients, NOT between the response variable and the explanatory variable(s).
 ,
, . In other words,
. In other words,  is the design matrix, and the element in row
is the design matrix, and the element in row  and column
and column  of this design matrix is the
of this design matrix is the  predictor being evaluated in the
predictor being evaluated in the  basis function. (In this case, there is 1 predictor per datum.)
basis function. (In this case, there is 1 predictor per datum.)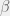 , can be estimated by
, can be estimated by .
. , but
, but  was obtained, I encourage you to review least-squares estimation and the derivation of the estimator of the coefficient vector in linear regression.
was obtained, I encourage you to review least-squares estimation and the derivation of the estimator of the coefficient vector in linear regression.


{kind=link}
Recent Comments