Mathematical Statistics Lesson of the Day – Complete Statistics
November 27, 2014 1 Comment
The set-up for today’s post mirrors my earlier Statistics Lesson of the Day on sufficient statistics.
Suppose that you collected data
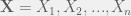
in order to estimate a parameter 
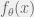

Let

be a statistic based on 
If
![E_\theta \{g[T(\mathbf{X})]\} = 0, \ \ \forall \ \theta,](https://s0.wp.com/latex.php?latex=E_%5Ctheta+%5C%7Bg%5BT%28%5Cmathbf%7BX%7D%29%5D%5C%7D+%3D+0%2C+%5C+%5C+%5Cforall+%5C+%5Ctheta%2C&bg=f0f0f0&fg=555555&s=0&c=20201002)
implies that
![P \{g[T(\mathbf{X})]\} = 0] = 1,](https://s0.wp.com/latex.php?latex=P+%5C%7Bg%5BT%28%5Cmathbf%7BX%7D%29%5D%5C%7D+%3D+0%5D+%3D+1%2C&bg=f0f0f0&fg=555555&s=0&c=20201002)
then 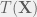
- let
be a measurable function
- if you want to use
to form an unbiased estimator of the zero function,
- and if the only such function is almost surely equal to the zero function,
- then
I will discuss the intuition behind this bizarre definition in a later Statistics Lesson of the Day.
*This above definition holds for discrete and continuous random variables.


Recent Comments