In my statistics classes, I learned to use the variance or the standard deviation to measure the variability or dispersion of a data set. However, consider the following 2 hypothetical cases:
- the standard deviation for the incomes of households in Canada is $2,000
- the standard deviation for the incomes of the 5 major banks in Canada is $2,000
Even though this measure of dispersion has the same value for both sets of income data, $2,000 is a significant amount for a household, whereas $2,000 is not a lot of money for one of the “Big Five” banks. Thus, the standard deviation alone does not give a fully accurate sense of the relative variability between the 2 data sets. One way to overcome this limitation is to take the mean of the data sets into account.
A useful statistic for measuring the variability of a data set while scaling by the mean is the sample coefficient of variation:

where  is the sample standard deviation and
is the sample standard deviation and  is the sample mean.
is the sample mean.
Analogously, the coefficient of variation for a random variable is
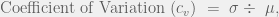
where  is the random variable’s standard deviation and
is the random variable’s standard deviation and  is the random variable’s expected value.
is the random variable’s expected value.
The coefficient of variation is a very useful statistic that I, unfortunately, never learned in my introductory statistics classes. I hope that all new statistics students get to learn this alternative measure of dispersion.
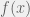 that is continuous on the interval
that is continuous on the interval ![[x_1, x_2]](https://s0.wp.com/latex.php?latex=%5Bx_1%2C+x_2%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) , where
, where 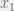 and
and 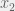 are any 2 points in the domain of
are any 2 points in the domain of 
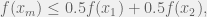
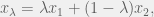 where
where 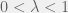 .
.

 with a finite expected value and for any convex function
with a finite expected value and for any convex function  ,
,![E[g(Y)] \geq g[E(Y)]](https://s0.wp.com/latex.php?latex=E%5Bg%28Y%29%5D+%5Cgeq+g%5BE%28Y%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.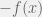 is convex. Thus, Jensen’s inequality can also be stated for concave functions. For any random variable
is convex. Thus, Jensen’s inequality can also be stated for concave functions. For any random variable  with a finite expected value and for any concave function
with a finite expected value and for any concave function  ,
,![E[h(Z)] \leq h[E(Z)]](https://s0.wp.com/latex.php?latex=E%5Bh%28Z%29%5D+%5Cleq+h%5BE%28Z%29%5D&bg=f0f0f0&fg=555555&s=0&c=20201002) .
.![P[|X - \mu| \geq k \sigma] \leq 1 \div k^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+1+%5Cdiv+k%5E2&bg=f0f0f0&fg=555555&s=0 "P[|X - \mu| \geq k \sigma] \leq 1 \div k^2")
 is most frequently observed near its expected value,
is most frequently observed near its expected value,  standard deviations away from
standard deviations away from  . Notice that this upper bound decreases as
. Notice that this upper bound decreases as  and
and  are finite. (Markov’s inequality
are finite. (Markov’s inequality ![V(X) = E[(X - \mu)^2], \ \text{where} \ \mu = E(X)](https://s0.wp.com/latex.php?latex=V%28X%29+%3D+E%5B%28X+-+%5Cmu%29%5E2%5D%2C+%5C+%5Ctext%7Bwhere%7D+%5C+%5Cmu+%3D+E%28X%29&bg=f0f0f0&fg=555555&s=0&c=20201002) .
. into
into  with another constant,
with another constant,  .
.
![P[(X - \mu)^2 \geq b^2] \leq E[(X - \mu)^2] \div b^2](https://s0.wp.com/latex.php?latex=P%5B%28X+-+%5Cmu%29%5E2+%5Cgeq+b%5E2%5D+%5Cleq+E%5B%28X+-+%5Cmu%29%5E2%5D+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[ (X - \mu) \leq -b \ \ \text{or} \ \ (X - \mu) \geq b] \leq V(X) \div b^2](https://s0.wp.com/latex.php?latex=P%5B+%28X+-+%5Cmu%29+%5Cleq+-b+%5C+%5C+%5Ctext%7Bor%7D+%5C+%5C+%28X+-+%5Cmu%29+%5Cgeq+b%5D+%5Cleq+V%28X%29+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[|X - \mu| \geq b] \leq V(X) \div b^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+b%5D+%5Cleq+V%28X%29+%5Cdiv+b%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
 with
with 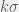 , where
, where 
![P[|X - \mu| \geq k \sigma] \leq V(X) \div k^2 \sigma^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+V%28X%29+%5Cdiv+k%5E2+%5Csigma%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
![P[|X - \mu| \geq k \sigma] \leq 1 \div k^2](https://s0.wp.com/latex.php?latex=P%5B%7CX+-+%5Cmu%7C+%5Cgeq+k+%5Csigma%5D+%5Cleq+1+%5Cdiv+k%5E2&bg=f0f0f0&fg=555555&s=0&c=20201002)
 where
where 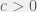 .
. becomes less probable.
becomes less probable. , then
, then ![P[X \geq E(X)] \leq 1](https://s0.wp.com/latex.php?latex=P%5BX+%5Cgeq+E%28X%29%5D+%5Cleq+1&bg=f0f0f0&fg=555555&s=0&c=20201002) ; this is the highest upper bound that
; this is the highest upper bound that  can get. This makes intuitive sense;
can get. This makes intuitive sense;  , then
, then 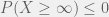 . By Kolmogorov’s axioms of probability, any probability must be inclusively between
. By Kolmogorov’s axioms of probability, any probability must be inclusively between 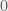 and
and  , so
, so  . This makes intuitive sense; there is no possible way that
. This makes intuitive sense; there is no possible way that 


Recent Comments