Applied Statistics Lesson of the Day – The Coefficient of Variation
August 12, 2014 3 Comments
In my statistics classes, I learned to use the variance or the standard deviation to measure the variability or dispersion of a data set. However, consider the following 2 hypothetical cases:
- the standard deviation for the incomes of households in Canada is $2,000
- the standard deviation for the incomes of the 5 major banks in Canada is $2,000
Even though this measure of dispersion has the same value for both sets of income data, $2,000 is a significant amount for a household, whereas $2,000 is not a lot of money for one of the “Big Five” banks. Thus, the standard deviation alone does not give a fully accurate sense of the relative variability between the 2 data sets. One way to overcome this limitation is to take the mean of the data sets into account.
A useful statistic for measuring the variability of a data set while scaling by the mean is the sample coefficient of variation:

where 

Analogously, the coefficient of variation for a random variable is
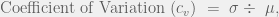
where 

The coefficient of variation is a very useful statistic that I, unfortunately, never learned in my introductory statistics classes. I hope that all new statistics students get to learn this alternative measure of dispersion.





Recent Comments