Background
Yesterday, I had the pleasure of attending my first Spring Alumni Reunion at the University of Toronto. (I graduated from its Master of Science program in statistics in 2012.) There were various events for the alumni: attend interesting lectures, find out about our school’s newest initiatives, and meet other alumni in smaller gatherings tailored for particular groups or interests. The event was very well organized and executed, and I am very appreciative of my alma mater for working so hard to include us in our university’s community beyond graduation. Most of the attendees graduated 20 or more years ago; I met quite a few who graduated in the 1950’s and 1960’s. It was quite interesting to chat with them over lunch and during breaks to learn about what our school was like back then. (Incidentally, I did not meet anyone who graduated in the last 2 years.)
A Thought-Provoking Lecture
My highlight at the reunion event was attending Joseph Wong‘s lecture on poverty, governmental welfare programs, developmental economics in poor countries, and social innovation. (He is a political scientist at UToronto, and you can find videos of him discussing his ideas on Youtube.) Here are a few of his key ideas that I took away; note that these are my interpretations of what I can remember from the lecture, so they are not transcriptions or even paraphrases of his exact words:
- Many workers around the world are not documented by official governmental records. This is especially true in developing countries, where the nature of the employer-employee relationship (e.g. contractual work, temporary work, unreported labour) or the limitations of the survey/sampling methods make many of these “invisible workers” unrepresented. Wong argues that this leads to inequitable distribution of welfare programs that aim to re-distribute wealth.
- Social innovation is harnessing knowledge to create an impact. It often does NOT involve inventing a new technology, but actually combining, re-combining, or arranging existing knowledge and technologies to solve a social problem in an innovative way. Wong addressed this in further detail in a recent U of T News article.
- Poor people will not automatically flock to take advantage of a useful product or service just because of a decrease in price. Sometimes, substantial efforts and intelligence in marketing are needed to increase the quantity demanded. A good example is the Tata Nano, a small car that was made and sold in India with huge expectations but underwhelming success.
- Poor people often need to mitigate a lot of risk, and that can have a significant and surprising effect on their behaviour in response to the availability of social innovations. For example, a poor person may forgo a free medical treatment or diagnostic screening if he/she risks losing a job or a business opportunity by taking the time away from work to get that treatment/screening. I asked him about the unrealistic assumptions that he often sees in economic models based on his field work, and he notes that absence of risk (e.g. in cost functions) as one such common unrealistic assumption.
The Importance of Checking the Quality of the Data
These are all very interesting points to me in their own right. However, Point #1 is especially important to me as a statistician. During my Master’s degree, I was warned that most data sets in practice are not immediately ready for analysis, and substantial data cleaning is needed before any analysis can be done; data cleaning can often take 80% of the total amount of time in a project. I have seen examples of this in my job since finishing my graduate studies a little over a year ago, and I’m sure that I will see more of it in the future.
Even before cleaning the data, it is important to check how the data were collected. If sampling or experimental methods were used, it is essential to check if they were used or designed properly. It would be unsurprising to learn that many bureaucrats, policy makers, and elected officials have used unreliable labour statistics to guide all kinds of economic policies on business, investment, finance, welfare, and labour – let alone the other non-economic justifications and factors, like politics, that cloud and distort these policies even further.
We statisticians have a saying about data quality: “garbage in – garbage out”. If the data are of poor quality, then any insights derived from analyzing those data are useless, regardless of how good the analysis or the modelling technique is. As a statistician, I cannot take good data for granted, and I aim to be more vigilant about the quality and the source of the data before I begin to analyze them.
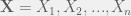
 . Let
. Let 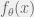 be the probability density function (PDF) or probability mass function (PMF) for
be the probability density function (PDF) or probability mass function (PMF) for  .
.
 .
. does NOT depend on
does NOT depend on 
 is the sample standard deviation and
is the sample standard deviation and  is the sample mean.
is the sample mean.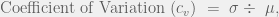
 is the random variable’s standard deviation and
is the random variable’s standard deviation and  is the random variable’s expected value.
is the random variable’s expected value.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Recent Comments