Using PROC SQL to Find Uncommon Observations Between 2 Data Sets in SAS
April 17, 2015 2 Comments
A common task in data analysis is to compare 2 data sets and determine the uncommon rows between them. By “uncommon rows”, I mean rows whose identifier value exists in one data set but not the other. In this tutorial, I will demonstrate how to do so using PROC SQL.
Let’s create 2 data sets.
data dataset1; input id $ group $ gender $ age; cards; 111 A Male 11 111 B Male 11 222 D Male 12 333 E Female 13 666 G Female 14 999 A Male 15 999 B Male 15 999 C Male 15 ; run;
data dataset2; input id $ group $ gender $ age; cards; 111 A Male 11 999 C Male 15 ; run;
First, let’s identify the observations in dataset1 whose ID variable values don’t exist in dataset2. I will export this set of observations into a data set called mismatches1, and I will print it for your viewing. The logic of the code is simple – find the IDs in dataset1 that are not in the IDs in dataset2. The code “select *” ensures that all columns from dataset1 are used to create the data set in mismatches1.


 and
and  , the chi-squared test of independence determines whether or not there exists a statistical dependence between them. Formally, it is a hypothesis test with the following null and alternative hypotheses:
, the chi-squared test of independence determines whether or not there exists a statistical dependence between them. Formally, it is a hypothesis test with the following null and alternative hypotheses:
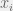 given
given 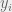 ). Check it out!
). Check it out!
 .
. random variables,
random variables,  , are independent and identically distributed,
, are independent and identically distributed, , is approximately normal, and this approximation is better as
, is approximately normal, and this approximation is better as 
![h(t) = \lim_{\Delta t \rightarrow 0} [P(t < X \leq t + \Delta t \ | \ X > t) \ \div \ \Delta t]](https://s0.wp.com/latex.php?latex=h%28t%29+%3D+%5Clim_%7B%5CDelta+t+%5Crightarrow+0%7D+%5BP%28t+%3C+X+%5Cleq+t+%2B+%5CDelta+t+%5C+%7C+%5C+X+%3E+t%29+%5C+%5Cdiv+%5C+%5CDelta+t%5D&bg=f0f0f0&fg=555555&s=0 "h(t) = \lim_{\Delta t \rightarrow 0} [P(t < X \leq t + \Delta t \ | \ X > t) \ \div \ \Delta t]") .
.
Recent Comments