My colleague, David Campbell, will be the feature speaker at the next Vancouver Data Science Meetup on Thursday, June 25. (This is a jointly organized event with the Vancouver Machine Learning Meetup and the Vancouver R Users Meetup.) He will present his research on approximate Bayesian computation and Markov Chain Monte Carlo, and he will highlight how he has used these tools to study the invasion of European earthworms in Canada, especially their drastic effects on the boreal forests in Alberta.
Dave is a statistics professor at Simon Fraser University, and I have found him to be very smart and articulate in my communication with him. This seminar promises to be both entertaining and educational. If you will attend it, then I look forward to seeing you there! Check out Dave on Twitter and LInkedIn.
Title: The great Canadian worm invasion (from an approximate Bayesian computation perspective)
Speaker: David Campbell
Date: Thursday, June 25
Place:
HootSuite (Headquarters)
5 East 8th Avenue
Vancouver, BC
Schedule:
• 6:00 pm: Doors are open – feel free to mingle!
• 6:30 pm: Presentation begins.
• ~7:45 Off to a nearby restaurant for food, drinks, and breakout discussions.
Abstract:
After being brought in by pioneers for agricultural reasons, European earthworms have been taking North America by storm and are starting to change the Alberta Boreal forests. This talk uses an invasive species model to introduce the basic ideas behind estimating the rate of new worm introductions and how quickly they spread with the goal of predicting the future extent of the great Canadian worm invasion. To take on the earthworm invaders, we turn to Approximate Bayesian Computation methods. Bayesian statistics are used to gather and update knowledge as new information becomes available owing to their success in prediction and estimating ongoing and evolving processes. Approximate Bayesian Computation is a step in the right direction when it’s just not possible to actually do the right thing- in this case using the exact invasive species model is infeasible. These tools will be used within a Markov Chain Monte Carlo framework.
About Dave Campbell:
Dave Campbell is an Associate Professor in the Department of Statistics and Actuarial Science at Simon Fraser University and Director of the Management and Systems Science Program. Dave’s main research area is at the intersections of statistics with computer science, applied math, and numerical analysis. Dave has published papers on Bayesian algorithms, adaptive time-frequency estimation, and dealing with lack of identifiability. His students have gone on to faculty positions and worked in industry at video game companies and predicting behaviour in malls, chat rooms, and online sales.

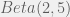 distribution actually integrates to 1 over its support set. This post follows from my previous post on
distribution actually integrates to 1 over its support set. This post follows from my previous post on 
 smaller intervals of equal lengths, and
smaller intervals of equal lengths, and 



Recent Comments